The Blind Less World
Problem Statement:
Globally, at least 2.2 billion people experience near- or distance-vision impairment, and of these, around 1 billion cases are preventable or untreated(World Health Organization) Visually impaired individuals face profound challenges navigating everyday environments — from urban streets and busy sidewalks to indoor spaces such as malls or workplaces(PMC) .Traditional mobility aids like white canes or guide dogs provide tactile or directional support but offer limited spatial awareness, little semantic context (“what is this object?”), and usually depend on external infrastructure or human assistance.

Current assistive technologies have evolved — wearable devices, smart canes, smartphone-based systems — yet a large review shows persistent limitations: dependence on cloud connectivity, inadequate indoor/outdoor obstacle differentiation, high cost, bulky design, and poor adoption in low-resource or rural environments(MDPI ).
There is therefore a critical need for a portable, affordable, fully offline, intelligent wearable solution that empowers visually impaired users to perceive, understand and interact with their surroundings independently — bridging the gap between conventional mobility aids and advanced smart systems that remain inaccessible to many.
Proposed Solution: “The Blind Less World”

The Blind Less World system is a next-generation AI-enabled wearable assistant designed to restore spatial awareness and autonomous mobility for visually impaired individuals.
Unlike conventional smart canes or app-based systems that rely on cloud computation or external connectivity, Blind Less World operates entirely offline, performing real-time object detection, obstacle recognition, and voice guidance directly on the embedded MAX78000FTHR microcontroller(which supports on-device neural network inference).
This edge-AI approach delivers instantaneous feedback, ensures privacy, and dramatically reduces energy consumption — enabling seamless, dependable navigation even in connectivity-restricted environments.
Parts & tools:
1.Hardware:
- MAX78000FTHR development board (MAX78000 CNN accelerator)
- Mini speaker or bone-conduction headset (for quiet, wearable use)
- Standard spectacles frame (to mount camera & board)
- Li-Ion battery + power management / boost board (e.g., 3.7V LiPo + charger)
2.Software & tools:
- Edge Impulse account (for data collection, model building and export)
- Python 3.8 (virtualenv) for conversion tools
- ai8x-synthesis / ai8xize.py (Analog Devices) for MAX78000 conversion
- MAX78000 SDK (for building example firmware)
- TensorFlow/TFLite (for model inspection)
- A desktop IDE (VS Code), serial terminal (PuTTY/TeraTerm)
- Audacity or TTS tool to produce voice prompts (or on-device small TTS engine)



How We Built It — The Making of “Blind Less World”
Data collection & labeling (Edge Impulse)
We use Edge Impulse to collect images and audio for each subtask.
Tasks and datasets
- Object/Obstacle detection: collect labeled images for chairs, walls, doors, vehicles, tables, stairs, steps.
- Face recognition (known persons): collect 100–300 images each for the 3–5 known people (varied lighting/angles).
- Keyword spotting (KWS): collect voice samples for commands like: “Hey guide”, “What’s there?”, “Scan steps”, “Color?”, “Who is this?”
- Color detection: color classification can be done by direct RGB analysis — collection optional (images with ground truth colors).
Edge Impulse pipeline (recommended settings)
- Project → Create dataset for each model (or a single multi-task project).
- Images: resolution 96×96 (your TFLite had 96×96×1 — you can convert to grayscale if needed).
- Architecture: lightweight MobileNet-like or small custom CNN (Edge Impulse image blocks).
- KWS: use Edge Impulse Audio/Spectrogram + k-nearest or small CNN classifier (keyword spotting template).
- Object detection: use Edge Impulse object detection block (bounding boxes).
Labeling tips
- Use Edge Impulse labelling tool; ensure varied backgrounds and lighting.
- Include negative examples for “no obstacle”.
- For step/stair detection, include up/down examples and curb edges.
Training & Export (Edge Impulse)
Steps:
- Train the model(s) inside Edge Impulse. For MCU: choose TensorFlow Lite (quantized int8) or C++ MCU (Edge Impulse’s tiny ML export).
- Test and validate — check confusion matrix and detection mAP.
- Export Quantized TFLite (int8) (this is what MAX78000 workflows expect).
- Download the zip and copy
model.tfliteto your development machine, intoC:\MAX78000_AI\ei-model\model.tflite(or repomodels/).
Notes: For MAX78000, quantized int8 is required for on-chip acceleration.
Inspect the TFLite & confirm input/output
Command (local, in your virtualenv):
# run a small inspect script (example)
import tensorflow as tf
interpreter = tf.lite.Interpreter(model_path='model.tflite')
interpreter.allocate_tensors()
print(interpreter.get_input_details())
print(interpreter.get_output_details())Verify:
- Input shape (should be
[1,96,96,1]or[1,96,96,3]) - Output shape (match expected labels or object map)
Convert model for MAX78000 (ai8xize workflow)
High-level steps (you’ve already tried this workflow — here’s a clean, repeatable version):
Create a clean workspace:
C:\> mkdir C:\MAX78000_AI C:\> mkdir C:\MAX78000_AI\ei-model C:\> copy path\to\model.tflite C:\MAX78000_AI\ei-model\model.tflite C:\> mkdir C:\MAX78000_AI\networks C:\> mkdir C:\MAX78000_AI\build C:\> mkdir C:\MAX78000_AI\testsIn your Python venv (
env78000) install dependencies:pip install rich numpy pyserial pyyaml onnx onnxruntime torch gitpythonFrom the
ai8x-synthesisrepo run autogen to generate a valid YAML for your TFLite:cd ai8x-synthesis python ai8xize.py --checkpoint-file C:\MAX78000_AI\ei-model\model.tflite --device MAX78000 --prefix C:\MAX78000_AI\build\anitect --test-dir C:\MAX78000_AI\tests --autogen C:\MAX78000_AI\networks\ai85-anitect.yaml --verbose
- If autogen works: it writes a MAX78000-compatible YAML and may produce code.
- If autogen fails, capture full error — fixes are YAML field name corrections (we debugged earlier).
Then run ai8xize with the
--config-file:python ai8xize.py --checkpoint-file C:\MAX78000_AI\ei-model\model.tflite --config-file C:\MAX78000_AI\networks\ai85-anitect.yaml --device MAX78000 --prefix C:\MAX78000_AI\build\anitect --test-dir C:\MAX78000_AI\tests --verbose- Confirm generated C files in
C:\MAX78000_AI\build\anitect(e.g.,model.c,model.h,weights.c).
In this way we create the all required models (for objects,known persons...etc)
Integrate with MAX78000 SDK & firmware
Steps
- Clone or unzip MAX78000 SDK (Analog Devices / Maxim repo).
- Pick an example project (image classification or object detection example).
- Replace the model files (
model.c,model.h, weights) into the example project. - Update
main.c:- Initialize camera capture (VGA or supported module)
- Preprocess frame (resize to 96×96, grayscale if needed)
- Call the model inference API (provided by generated code)
- Convert output to text (label or distance estimate)
- Feed label to the audio output code
- Add keyword spotting hook: if command recognized, perform requested action
BOARD=FTHR_RevA make BOARD=FTHR_RevA load
- Flash to MAX78000FTHR and open serial monitor (115200) to view logs.
- Firmware features:
- Modular tasks: camera → preprocess → inference → postprocess → audio
- Voice command: keyword spotting (local): wakeword + command
- Power management: sleep between frames or reduce frame rate
.jpg)
Audio feedback:
Pre-recorded messages: small and energy-efficient (e.g., “Chair ahead 1.2 meters” chunks). Use a small audio player or store WAVs in flash.
Voice commands & keyword spotting:
- Use Edge Impulse or a KWS model trained on your phrases (small int8 model).
- On wakeword detection, run higher-cost tasks (face recognition, distance estimation).
Keep KWS always-on at low power; only run heavier vision tasks after wakeword.
Commands examples
- “Hey guide” → activates system
- “What is in front?” → responds with nearest object
- “Who is this?” → triggers face recognition
- “Scan steps” → runs stair/step detector
Distance estimation:
- use ultrasonic sensor for better accuracy.

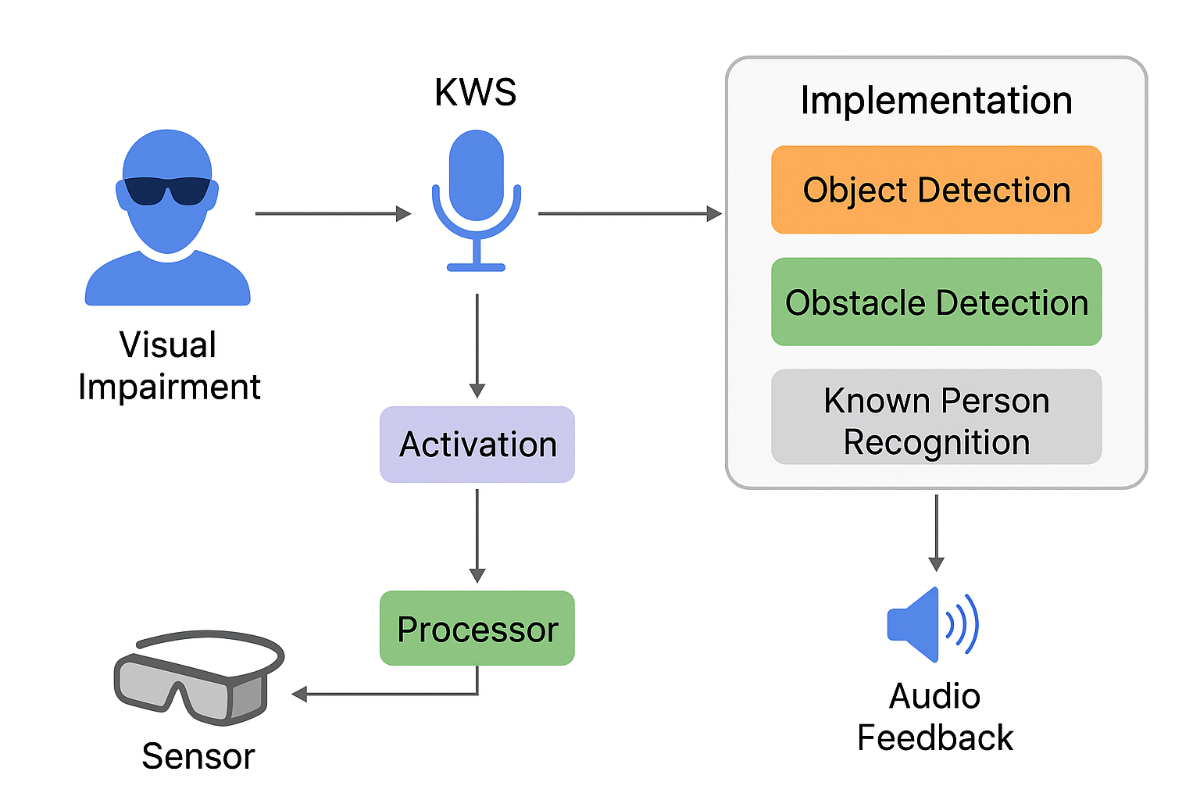
WORKING:
1. Device Initialization
- The wearable device powers on and initializes all sensors and AI modules.
- Sensors such as camera, ultrasonic and microphone are activated.
- The system performs a self-check and confirms readiness via audio feedback.
2. Voice Command Activation
- The device continuously listens for specific keywords.
- Upon detecting a command,the corresponding module is activated.
- This allows hands-free operation of all functionalities.
3. Object Recognition & Obstacle Detection
- The camera captures images of the surroundings.
- AI-based vision models identify objects such as doors, shelves, items, or obstacles.
- Detected objects are announced through audio, helping users locate and interact with them independently.
4. Person Recognition
- The system identifies known individuals from pre-stored images using facial recognition.
- Users receive audio alerts about familiar people nearby, enhancing social interactions and awareness.
5.Distance Estimation
- Using readings from ultra sonic sensor used to detect distance from the object or obstracle
Input: Camera captures a person in front of the user
face = camera_capture_face();
person_name = recognize_face(face);
if(person_name != None) {
if (person_name= "a"){
audio_play("a.wav");
}
if (person_name= "b"){
audio_play("b.wav");
}....etc
} else {
audio_play("Unknown.wav");
}
Input: Camera detects objects like stairs, vehicles, doors..etc
objects = detect_objects(frame);
for obj in objects:
if obj in critical_objects:
audio_play("obj.wav");
vibrate_alert();
Input: Ultrasonic sensor detects distance
distance = read_ultrasonic();
if(distance < SAFE_DISTANCE) {
vibrate_alert();
audio_play("distance.wav");
}
COMPARSION TABLE:
| Feature | White Cane | Smart Cane (IoT-based) | The Blind Less World (Proposed) |
|---|---|---|---|
| Detection Range | Very short (touch only) | Medium (ultrasonic) | Long-range (AI vision) |
| Internet Dependence | ❌ | ✅ Required | ❌ Offline |
| Object Identification | ❌ | ❌ | ✅ (on-device) |
| Voice Feedback | ❌ | ❌ | ✅ (custom) |
| Portability | ✅ | ⚠️ (bulky sensors) | ✅ (wearable) |
| Cost | Low | Medium–High | Low–Medium |
| Power Requirement | None | Medium | Low |
| Scalability | Manual | Limited | High (open-source + modular) |
Unique Features/Uniqueness of this Project:
- Completely Offline Operation – No dependency on internet or smartphone apps.
- AI on Microcontroller – Utilizes MAX78000’s hardware CNN accelerator for edge inference.
- All-in-One Design – Combines obstacle detection, persons detection, distance estimation,Kws controlling,voice feedback, and safety alerts in a single wearable unit.
- Energy Efficient – Runs on minimal power with potential for solar recharge.
- Affordable Accessibility – Built with low-cost, open-source components for developing regions.
Final Conclusion:
Blind Less World represents a comprehensive, AI-powered assistive wearable designed to empower visually impaired individuals with enhanced mobility, safety, and independence. By integrating multi-sensor perception, AI-driven decision-making, and voice/haptic feedback, the system addresses real-world challenges—such as obstacle detection, navigation, and social interaction—effectively and efficiently.
The project not only solves critical daily problems for the visually impaired but also introduces unique features like keyword-activated modules, real-time object/person recognition, and environmental awareness. Its modular design ensures scalability, future upgrades, and adaptability to different use cases, making it a practical, life-changing innovation.
In essence, Blind Less World transforms technology into a trustworthy companion, bridging the gap between disability and independence, and sets a foundation for next-generation smart assistive devices.
DEMO VIDEO: